Benchmarks¶
Warning
The following benchmarks are for general orientation only. Benchmark results are highly platform dependent; your mileage may vary.
See also
See our recent paper Fast, Cheap, and Turbulent—Global Ocean Modeling With GPU Acceleration in Python for more in-depth benchmarks, results, and interpretations.
Varying problem size¶
This benchmark varies the size of the computational domain and records the runtime per iteration. It is executed on a single machine with 24 CPU cores and an NVidia Tesla P100 GPU.
We run the same model code with all Veros backends (numpy, numpy-mpi, jax, jax-mpi, jax-gpu) and PyOM2 (fortran, fortran-mpi).
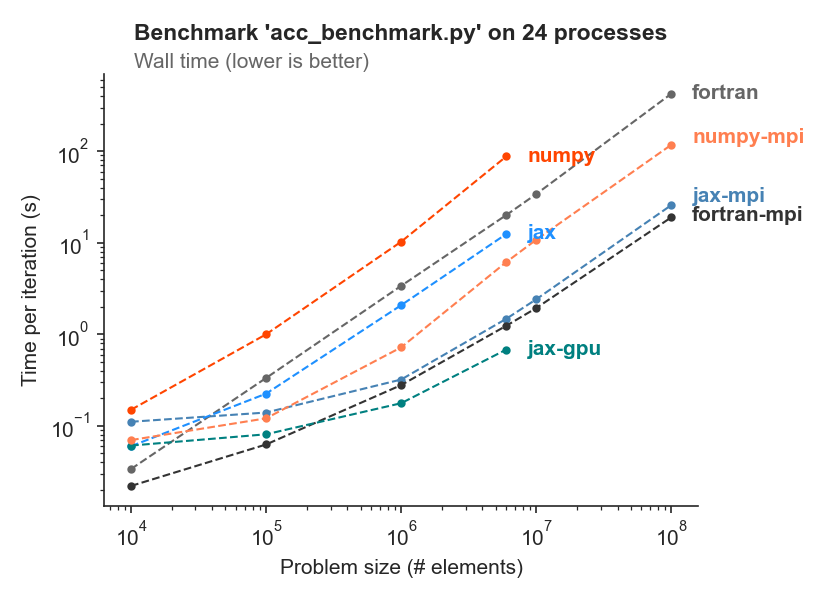
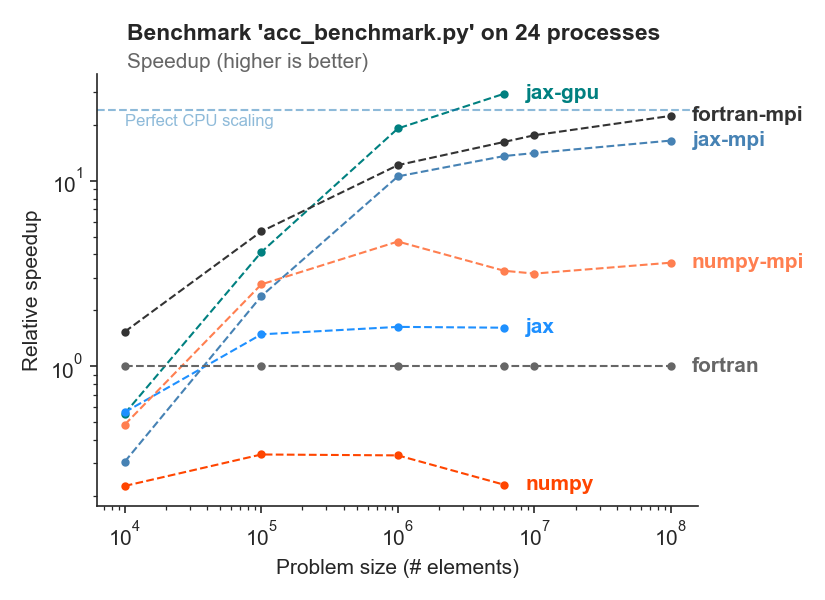
As a rule of thumb, we find that JAX is about as fast as Fortran on CPU, with NumPy being about 4x slower. GPUs are a competitive alternative to CPUs, as long as the problem fits into GPU memory.
Varying number of MPI processes¶
In this benchmark, Veros and PyOM2 run for a fixed problem size, but varying number of processes. This allows us to check how both models scale with increased CPU count. The problem size corresponds to 1 degree global resolution.
It is executed on the DC³ cluster. Each cluster node contains 16 CPUs.
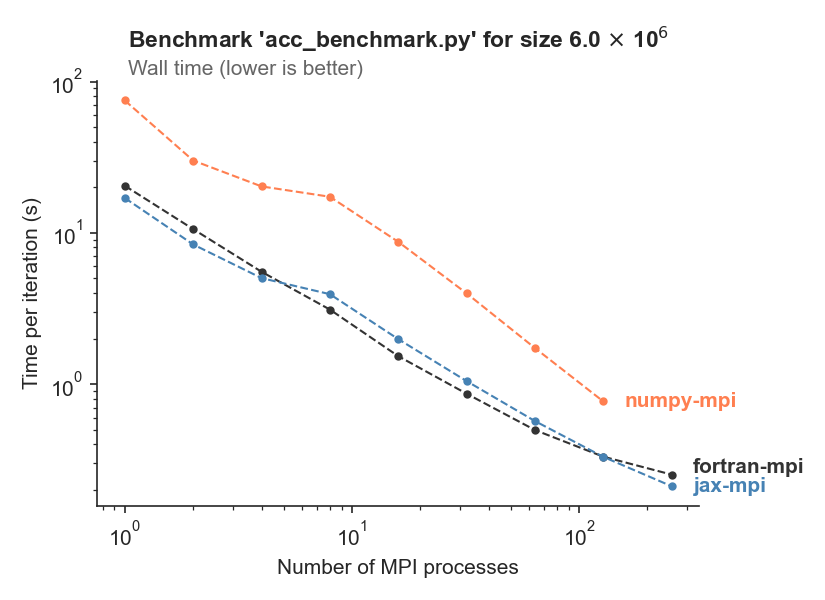
We see that both Veros and PyOM2 scale well with increasing number of processes, even for this moderate problem size. JAX performance is comparable to Fortran.